Polars: The Must-Know Data Frame Library Every Data Scientist Should Know
A complete guide on Polars Dataframe Library

If you are not a member of Medium- read the story for free here!
Pandas is a well-known library that every data scientist uses when dealing with data frames. But sometimes it is inefficient when dealing with large datasets. If you’re quite familiar with pandas, then you’ll find Polars to be an exciting alternative in such cases.
In this article, we are going to learn about this very useful tool for large-scale data analysis.
Please don’t forget to follow, clap👏, and add your feedback in the comments,🥰 Thanks !!!
Let's get started!
The Polars library is a very lightweight library developed in Rust Language that can be used in Python. It offers an extensive range of features that make a variety of data manipulation and analysis tasks easier, and it also doesn’t have any dependencies. Due to its scalability and efficient framework, Polars is considered a healthy alternative to Pandas.
Why Use Polars?
Since pandas have been around since the beginning, why do we feel the need to switch to polar now? Let's see!
- Speed: Polars is designed to do parallel processing and it’s written in Rust which is a systems programming language known for its performance. This makes Polars much faster than pandas. Due to its zero-dependency nature, Polars have much shorter import times than Pandas.

2. Efficiency: Polars is designed to handle large datasets efficiently, both in terms of speed and memory usage by supporting multi-threading. It has inbuilt memory optimization techniques that utilize all available cores on your machine, making Polars capable of handling large datasets in a streaming fashion.
3. Performance: Polars is based on the Apache Arrow specification’s safe Arrow2 implementation. Arrow can be thought of as middleware that enables highly cache-coherent data structures for Data Frame libraries. It helps to handle missing values and data filtering very easily.
4. Optimization: Polars support two types of optimizations — Eager evaluation programming & Lazy Evaluation programming. The former is the normal way of querying where the data is processed immediately when an operation is called, and the latter allows the computations to be delayed until necessary. It builds a query plan first, optimizing it for performance, and then executes the plan. This can lead to significant performance gains.
How to install Polars?
Before learning the commands, let’s see how to install Polars. We can install it using Python’s package manager, pip.
pip install polarsBy default, the pip installs polars allow for approximately 4.2 billion rows (2³²). If you need to support larger data frames, you can install the polars-u64-idx version using pip install polars-u64-idx.
Import and Exporting to Pandas
Polars can effectively incorporate the data frames that we already read using pandas. The below command takes the pandas data frame as input and creates a Polars data frame.
polar_df = pl.from_pandas(pandas_df)Polars also offers a variety of import options, including reading data from CSV or TSV files using pl.read_csv(), Parquet files with pl.read_parquet(), Arrow tables via pl.from_arrow(), and creating DataFrames from dictionaries with polars.from_dict(), polars.from_dicts(), and even reconstructing DataFrames from their string representations using polars.from_repr() that makes it a versatile tool for efficient data manipulation.
Likewise, we can convert/ export polars data frames to pandas too.
pandas_df = polars_df.to_pandas()Other than these, Polars offers a variety of export features including converting data to Arrow format using to_arrow, exporting to dictionaries with to_dict or to_dicts, and even providing Torch support via to_torch .
Important Commands in Polars
There are a lot of commands available in polars for different use cases. For better understanding, I grouped the majority of them based on their use to find the commands you need for your specific task easily.
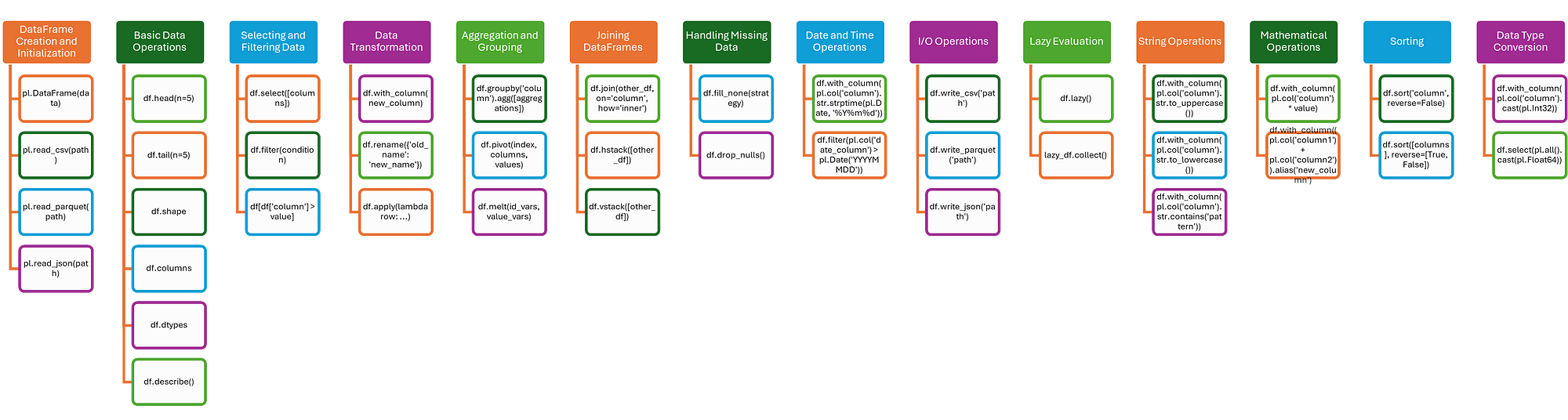
Let's see the list of commands.
You may think that the majority of Polars commands resemble those in pandas, which makes it easier for pandas' users to transition to Polars. However, several key differences make Polars stand out, especially when dealing with large datasets and performance-critical applications.
Data Frame Creation and Initialization
These commands are used to create and initialize Data Frames from various data sources.
pl.DataFrame(data): This is the most basic way to create a data frame in Polars from a dictionary, list of lists, or other data structures.
import polars as pl
data = {
"name": ["Alice", "Bob", "Charlie"],
"age": [25, 30, 35]
}
df = pl.DataFrame(data) pl.read_csv(path): This command is used to load data/ read a CSV file into a data frame.
df = pl.read_csv("path/to/your/file.csv") pl.read_parquet(path): Parquet is a columnar storage file format optimized for use with big data and this command is used to read a Parquet file into a Data Frame.
df = pl.read_parquet("path/to/your/file.parquet") print(df)pl.read_json(path): This is useful for working with JSON data structures to read a JSON file into a data frame.
df = pl.read_json("path/to/your/file.json")Basic Data Operations
These commands provide basic operations to inspect and understand the structure of your data frame.
df.head(n=5): This displays the firstnrows of the data frame. The default is 5 rows.
print(df.head())df.tail(n=5): This command is used to display the lastnrows of the data frame. The default is 5 rows.
print(df.tail())df.shape: Used to get the shape (number of rows and columns) of the data frame.
print(df.shape)df.describe(): This is a very useful command in exploratory data analysis to generate descriptive statistics of the data. It will summarize the central tendency, dispersion, and shape of a dataset’s distribution, excluding the NaN values in the data set.
print(df.describe())Selecting and Filtering Data
These commands are used to select specific columns or filter rows based on conditions.
df.select([columns]): Used to select specific columns by its name.
print(df.select(["name", "age"]))df.filter(condition): Command used to filter rows based on a specific condition.
filtered_df = df.filter(pl.col("age") > 30) print(filtered_df)Data Transformation
These commands allow you to add, modify, or apply functions to Data Frame columns.
df.with_column(new_column): This is useful for adding or modifying a column.
df = df.with_column((pl.col("age") * 2).alias("double_age"))df.rename({'old_name': 'new_name'}): We will make use of this command to rename columns.
df = df.rename({"age": "years"})df.apply(lambda row: ...): This command is used to apply a function to each row or column.
df = df.apply(lambda row: row['age'] * 2, axis=1)Aggregation and Grouping
These commands are used to perform aggregation operations and group data.
df.groupby('column').agg([aggregations]): To Group by one or more columns and apply aggregation functions.
grouped_df = df.groupby("name").agg(pl.col("age").mean())df.pivot(index, columns, values): Used to pivot a data frame, reshaping data from long to wide format.
pivot_df = df.pivot(index="name", columns="year", values="score")df.melt(id_vars, value_vars): This command is used to unpivot a data frame from wide format to long format.
melt_df = df.melt(id_vars=["name"], value_vars=["score"])Joining Data Frames
These commands allow you to join or concatenate Data Frames.
df.join(other_df, on='column', how='inner'): To join two Data Frames on a key column.
df1 = pl.DataFrame({"name": ["Anu", "Scaria"], "age": [25, 30]})
df2 = pl.DataFrame({"name": ["Angel", "Jacob"], "height": [165, 175]})
joined_df = df1.join(df2, on="name", how="inner")df.hstack([other_df]): Used to horizontally stack another data frame or Series.
hstacked_df = df1.hstack([df2])df.vstack([other_df]): This one is used to vertically stack another data frame or Series.
vstacked_df = df1.vstack([df2])Handling Missing Data
Handling missing data is one of the most important steps in data science. These commands help handle and manipulate missing data.
df.fill_none(strategy): Used to fill missing values with a specified strategy ('forward', 'backward', etc.).
df = df.fill_none("forward")When you apply forward fill, missing values are replaced with the most recent non-missing value that occurred before the missing data point. In contrast, backward fill replaces missing values with the most recent non-missing value that occurred after the missing data point.
df.drop_nulls(): This is used to drop rows with any missing values.
df = df.drop_nulls()Date and Time Operations
These commands are used to manipulate date and time data.
df.with_column(pl.col('column').str.strptime(pl.Date, '%Y-%m-%d')): Used to convert string to Date type.
df = df.with_column(pl.col("date").str.strptime(pl.Date, "%Y-%m-%d"))df.filter(pl.col('date_column') > pl.Date('YYYY-MM-DD')): This command is used to filter rows based on date.
filtered_df = df.filter(pl.col("date") > pl.Date("2021-01-01"))I/O Operations
These commands are used to read from and write to various file formats.
df.write_csv('path'): This command is to save the DataFrame to a CSV file.
df.write_csv("output.csv")df.write_parquet('path'): Similarly, this one is used to save the DataFrame to a Parquet file.
df.write_parquet("output.parquet")df.write_json('path'): This is used to save the DataFrame to a JSON file.
df.write_json("output.json")Lazy Evaluation
These commands enable lazy evaluation, which can optimize query execution.
df.lazy(): This is used to convert a DataFrame to a LazyFrame for lazy evaluation.
lazy_df = df.lazy()lazy_df.collect(): Used to execute the lazy operations and collect the results.
result = lazy_df.filter(pl.col("age") > 30).select(["name", "age"])
print(result.collect())String Operations
These commands are used to perform various operations on string columns.
df.with_column(pl.col('column').str.to_uppercase()): Make use of this command to convert strings to uppercase.
df = df.with_column(pl.col("name").str.to_uppercase())df.with_column(pl.col('column').str.to_lowercase()): Used to convert strings to lowercase.
df = df.with_column(pl.col("name").str.to_lowercase())df.with_column(pl.col('column').str.contains('pattern')): To check if strings contain a pattern.
df = df.with_column(pl.col("name").str.contains("li"))Mathematical Operations
These commands allow you to perform mathematical operations on DataFrame columns.
df.with_column(pl.col('column') * value): This command is used to multiply column values by a constant.
df = df.with_column((pl.col("age") * 2).alias("double_age"))df.with_column(pl.col('column1')+pl.col('column2')))command is used to perform element-wise operations on columns.
df = df.with_column((pl.col("age") + pl.col("score")).alias("total"))Sorting
These commands help in sorting the data frame based on column values.
df.sort('column', reverse=False)used to sort the data frame by a specific column in ascending or descending order.
df = df.sort("age", reverse=True)df.sort([columns], reverse= [True, False])to sort by multiple columns with specified orders.
df = df.sort(["age", "score"], reverse=[True, False])Data Type Conversion
These commands allow you to convert the data types of columns in the Data Frame.
df.with_column(pl.col('column').cast(pl.Int32))helps to cast a column to a different data type.
df = df.with_column(pl.col("age").cast(pl.Int32))df.select(pl.all().cast(pl.Float64))to cast all columns to a specific type.
df = df.select(pl.all().cast(pl.Float64))Conclusion
Polars is a very efficient alternative to pandas, especially suited for handling large datasets. Since it is designed with great optimization features, it is suitable for large data manipulations and analysis. It allows seamless conversion between pandas and other data structures. Its similarity with pandas' commands helps us to learn Polars easily.

